Jupyter notebook on HDF5, h5py, PyTables, Datashader
Last month at a PyDataMunich meetup I gave a short workshop on HDF5 and the python packages that we can use when dealing with HDF5 files.
I started the workshop with this picture:
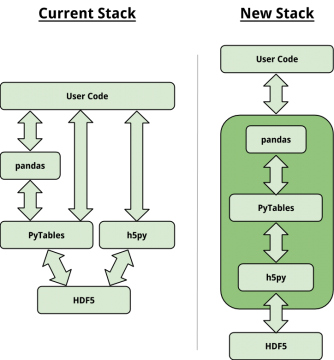
As you can see, at the moment python developers have to make a choice between h5py and PyTables.
h5py provides a low-level, pythonic interface to the entire C HDF5 library. PyTables takes a different route and provides high-level abstractions that can make your life easier when writing to HDF5 or searching data in a HDF5 file. It also implements compression and chunking for you. You could say PyTables is more “battery included”.
I have more experience with PyTables, so I am a little bit biased towards it.
What I really like about these projects is that they have very different philosophies, and for this reason the mainteners agreed to work together in creating a new python stack for HDF5.
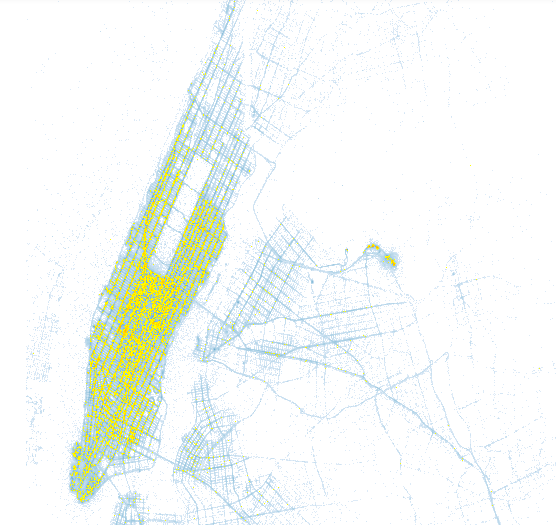
It took me quite a while to prepare this workshop, but it was a great opportunity to play with the New York City taxi dataset and try out Datashader, an innovative data rasterization pipeline that can be used to create data visualizations from massive datasets.
Here is an image I generated from the yellow taxis data from January 2015. Pickup locations are shown in blue. The pickup locations resulted from a search are shown in yellow.
Snippets and notebook are available on this GitHub repo.